
Key Takeaways:
- Lava’s seed funding points to a broader trend: payments infrastructure is adapting for a future where AI agents make purchasing decisions. Big players like Visa, Mastercard, and PayPal are already laying the technical groundwork to let bots transact, and that raises fresh questions about permissions and security.
- DeepMind’s latest world model makes synthetic environments feel more continuous and explorable. But while the illusion is stronger, the system still fails to obey the internal rules of the world it presents, revealing a gap between representation and genuine simulation that matters for industries built around material and spatial truth.
- For consumers, visual shortcuts often suffice. But teams working on fit-critical or experience-driven products need more than a plausible surface. Treating approximate outputs as simulations risks undermining the very workflows and standards those sectors rely on.
Digital Wallets For AI Agents
The interesting thing about AI’s product era is that products come in all shapes and sizes – from gigantic pre-existing platforms being given new AI capabilities, to founders with new concepts going after new categories. Lava is an example of the latter: a startup you’ve probably never heard of, that just raised $5.8 million in seed funding to build a solution to a problem that doesn’t really exist yet, at least not at scale …digital wallets for the AI agents, chatbots, scripts, and assistants that tech giants tell us will soon be picking out your gifts, buying your food, and maybe purchasing your next pair of shoes.
We may be seeing this through one company’s lens, but Lava’s pitch aligns with a series of converging trends we’ve been observing for the past year or so: the idea that online commerce is slowly moving away from humans making choices in real time; the prediction that AI agents, acting on people’s instructions, will be the “users” for a lot of web-based apps and services; and the assumption that, when that happens, the current payment system (which typically requires the user to step back in, credit card in hand) won’t be fit for purpose.
On their own, Lava is the kind of two-steps-forward company that wouldn’t warrant one of these analyses. But they’re not alone. Legacy heavyweights like Visa, Mastercard, and PayPal are also experimenting with infrastructure tailor-made for agent-led transactions. Visa has described a vision of “intelligent commerce”, and Mastercard has pushed forward in tokenization and fraud prevention, hinting at use cases where agents could transact on individuals’ behalves, without exposing sensitive card holder data. Meanwhile, Paypal and Venmo have partnered with Perplexity with the aim to turn AI conversations into AI-native checkouts.

Taken on aggregate, this sure sounds like a bet that conversations with AI agents are going to replace at least some of the current paradigm of web traffic, even if they are too widely-distributed to lead to the kind of consolidation that would make them “the new Google”. And implicit in this gamble is the understanding that those platforms will (just as the combination of backend systems that make up payment processing on the web today already are) be doing more than just transacting money; they’ll be responsible for enforcing permissions, confirming identities, detecting fraud, and keeping users safe from unintended spending.
That means the sensitivity of the data at play goes up. Wallets will be holding the keys to bank details, account permissions and spending authority. If a bot makes a purchase on your behalf, the wallet has to confirm that it’s allowed, and if that system fails, the consequences (accidental charges, issued credentials, outright fraud) can be serious.
This is especially relevant in high-velocity consumer categories like fashion, where the purchase cycle is fast, the return rate high, and identify fraud is already a known risk. AI agents might make shopping easier, but they also introduce new surface risk areas, and new dependencies on whoever sits between the agent and the transaction.

So while this week’s Lava news is a small part of the puzzle, the company is part of a much larger move – one where some of the world’s biggest payment platforms are building the infrastructure for a new kind of online shopping, built for a new kind of buyer. And a kind of shopping that The Interline has been covering in detail for a while now.
Simulation Vs Representation
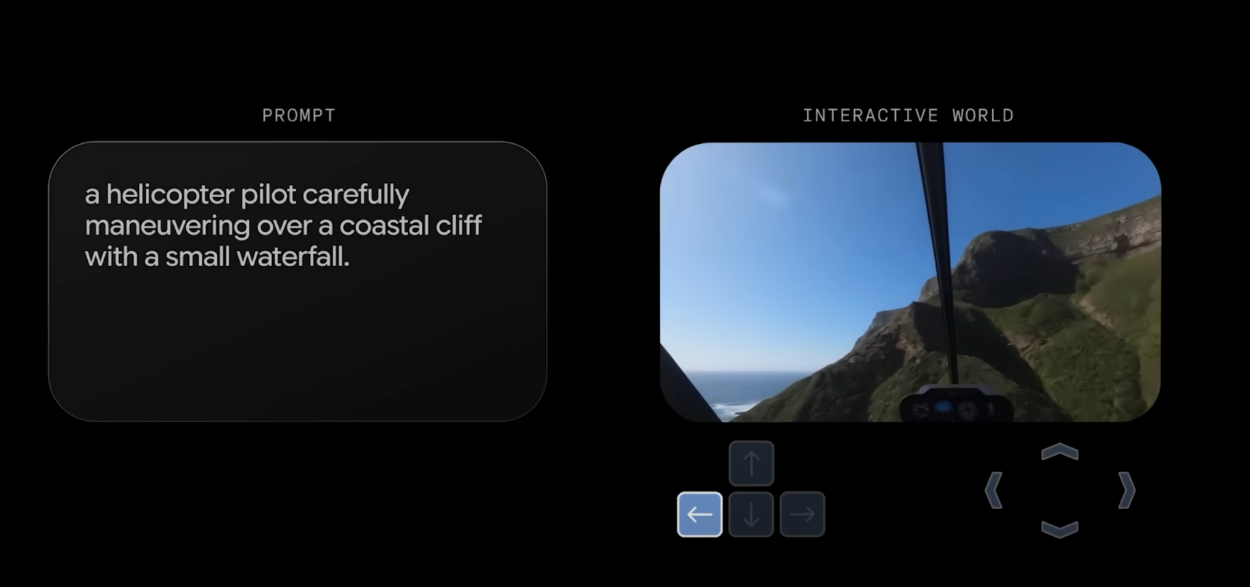
Elsewhere on the AI spectrum this week, Google Deepmind introduced Genie 3, the latest iteration of its “world model” AI, designed to simulate real world dynamics and generate interactive 3D environments, with one of the stated purposes being that synthetic environments will provide a place for agents to learn and safely test their operating parameters.
But while that’s one vision Google has for the outputs of this research, the more likely use case will be end users looking to step into other worlds for a few minutes – either ones they prompt and generate for themselves, or worlds created by brands. And in both cases, the definition of what a world model actually is (and where that diverges from what it’s being described as being) is extremely important.
In their announcement, DeepMind shared a series of impressive demo videos that showcased the model powering both navigation of AI-generated environments in real time, at 720p resolution and 24 frames a second (a clear upgrade over previous version), and what Google refers to as “promptable world events” where the user inputs a new prompt that translates into something new appearing in the environment – like a man in a chicken suit, a jetski and a dragon all appearing in a scene depicting a walk along an otherwise unremarkable city canal.
Control tools for navigation within Genie 3 are simple:, directional arrows or screen edge prompts that let you move the viewpoint and explore generated space at whatever pace the scenario dictates. (What constitutes ‘control’ obviously varies when the player’s perspective is moving at a walking pace compared to how it looks when the ‘camera’ is barrelling down a snowy mountainside.)

But the most significant upgrade over Genie 2 is in temporal and spatial consistency. In earlier versions, elements that left the camera frame were quickly lost, only to be regenerated (sometimes subtly different; sometimes replace wholesale) if the viewpoint turned back, which broke any sense of these experiences being a representation of persistent space. Genie 3 extends that memory horizon considerably, maintaining off-screen elements for longer periods of time and supporting continuous interaction over the course of several minutes. That longer window is a leap in both visual coherence and the duration of interactivity, bringing the generated environments closer to something that feels stable and explorable, instead of being stitched together moment to moment.
At first glance, then Genie 3 feels like a direct broadside fired against the entire discipline of creating real-time scenes and interactive experiences. It’s clearly not ready to be counterpositioned against videogames, which layer logic, scripting, instancing etc. on top of real-time graphics, but Genie 3 still. gestures towards a future where environments don’t need to be modelled,, lit, or textured by hand, and can simply be prompted into existence.
But how far does that gesture actually extend?
For fashion and beauty, that’s a question with a timeline attached to it, because the next frontier of 3D isn’t just about better renders but about contextual storytelling. Whether its teams designing branded environments, or a consumer stepping into the “mood” around a product, one of the pathways forward from large-scale creation of digital products is building environments and experiences that those products can exist within. Right now, doing that still takes work. It means creating concepts from scratch, building the assets, applying materials, lighting the scene, and then rendering it, either locally or on the cloud. There are tools that make that process faster, and that lighten the lift on local hardware, but there’s currently no dramatic shortcut around the artistic and technical lift required to create a branded experience that a user can step into and navigate.
If you’re close to that workflow, this push towards “world models” can look like a shortcut or a threat, depending on where you stand. Should brands be looking at generation as a viable near-term alternative to existing digital content creation pipelines for building immersive experiences? And what would it mean for existing content, technical artistry, and design teams if it was?
The answer sits on what sounds like a philosophical question, but quickly becomes a very practical one: what actually counts as simulation?
Genie 3 doesn’t claim to simply generate scenes, it claims to simulate the natural world. The demo page references “vibrant ecosystems” and the ability to model “complex environmental interactions.” These are all things that are traditionally very computationally intensive to do through actual simulation, because that word carries a very specific meaning: fluid and cloth simulations, for instance, do not aim to just roughly approximate the way water or clothing moves; they aim to virtualise the essential properties of those mediums in an internally consistent system that then recreates the behaviour of those things from first principles.
In that world, a cloth simulation isn’t just trying its best to look like a fabric, it is aiming to behave like a fabric would. We don’t build a garment simulation system by just looking at lots of dresses and then recreating the way they look to the observer. We judge whether it’s good based on how a garment moves, how it stretches, where it folds, and how it reacts to gravity – all in ways that demonstrate internal logic, consistency, and repeatability.
Since the first wave of video generation models emerged, there’s been a tendency – including amongst people who should really know better – to imply that just because a model can generate convincing water, for example, it must somehow instinctively understand fluid dynamics. But looking like a thing, and behaving like that thing, are not the same.

If an AI can generate an image that resembles the output of a complex system, a splash or a roll of paint, does that mean it has a model of how the different parts of that system works? Or is it simply reproducing something that looks like the right answer, without understanding why?
That distinction might sound academic, but for teams working in 3D environments with fit-critical products, draped garments, animated materials, and spatial consistency, it matters a lot more than it seems.
The Interline’s position on this has been consistent since the conversation round AI-generated video first began: no, representation and simulation are not equivalent.
A model that truly simulates something doesn’t just generate a plausible visual result, it obeys the rules of the system it outwardly represents. And where it doesn’t obey those rules, because of limitations in the model, or due to an unreasonably high computational overhead, those instances are rightly judged as failings.
In the case of Deepmind’s paint roller demo, a genuine simulation would account for the viscosity of the paint, the surface texture of the wall, and the way those two things interact when pressed together. It wouldn’t apply it from inconsistent distances, or let objects interact without actually making contact, because these would not be feasible outcomes of a system that accurately modelled those things.
Yet that’s exactly what happens. As impressive as the “painting a wall” demo of Genie 3 is, it breaks down when you examine it through that lens. It’s a much more persuasive illusion than we’ve seen before, with a longer context window, but it’s still an illusion. And it’s not just in the painting clip, but across several other demos. A stormy sea spills onto a road then pulls back in a way that feels disconnected from the way we know water would actually recede. Or that canal jetski distributes oddly repetitive patches of water onto the towpath. This is the kind of thing that happens when a system is generating the appearance of simulation, but isn’t really simulating everything (or even anything) underneath.

This is where the term “world model” becomes contentious. If a model repeatedly breaks the physical logic of the world, in how objects move and interact, can it really be said to be modelling that world? Or is it simply doing a very good job of looking like it does?
Adding interactivity over a longer horizon doesn’t resolve the underlying question, but it does bring us closer to a more practical one: does anyone actually care?
To take the painting example further, does the typical end user who just wants to get a quick idea of how a wall would look in a different colour mind if the roller sometimes clips through the wall, or hits it from a bit too far away? Probably not. Does an interior designer care if a couch moves a couple of feet, or the cushions change, over the course of a few minutes? Maybe. Does a project manager for construction care if an architrave meets a wall in a way that isn’t really achievable, or an air vent is positioned in a way that isn’t strictly up to code? Definitely.
These are judgement calls, and they sit on a sliding scale of tolerance that’s entirely use-case specific, but that same continuum plays out across fashion and beauty. A consumer browsing online likely doesn’t need exacting physical realism, they’re usually happy with something that captures the essence of the thing they’re thinking about buying. Teams deeper in the chain though, have different needs, and technical users will always demand precision and accuracy, because an approximation is rarely good enough to make an informed decision on top of.
That’s the fundamental difference between simulation and representation. A simulation offers a system that behaves consistently, even as the use case changes. A representation doesn’t. It might look convincing in one scenario, but fall apart in another, and when the visual output is this compelling, it’s easy to let that inconsistency slide, to treat results as good enough without properly interrogating the process underneath it.
The thing is, this is one area of AI where hype can be not just wrong but actively damaging, because calling something a simulation that isn’t does a dramatic disservice to what a simulation actually is to begin with. And in fashion and beauty’s use cases, as product-centric industries where the experience has to be backed by a reality that lands in people’s hands, on their bodies, or on their skin, that’s a distinction that really matters.